@Moacir_Ferreira os meus posts servem apenas de “alerta” foi algo que eu nao reparei quando optei por mudar de exsi para proxmox e desta forma aproveitar o HA… porque lá está o proprio homeassistant não está pensado para funcionar dessa forma.
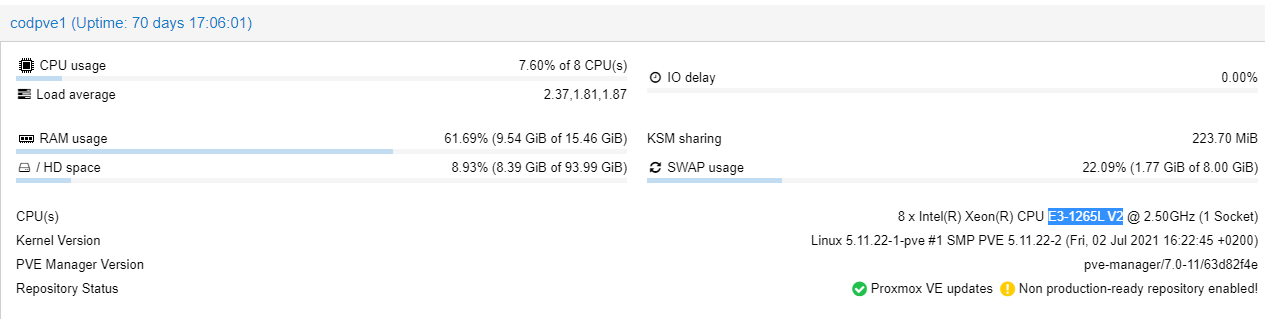
No meu caso especifico o problema o delay não é tanto do “hardwar”, apesar de correr em servidor os discos são domesticos, sdd, mas domésticos, no entanto para homelab as specs ão são assim tao fracas quanto isso. Prova, que usando um servidor normal não tem qualquer problema quando tem a carga toda que antes estava repartido por 3 nós.
Tive alguns cuidados, de usar os mesmos componentes em todos os nós.
A unica diferença para o caso do Luis, do que vimos na altura era a capacidade dos discos e o tipo, ele tem discos nvme e de menor capacidade.
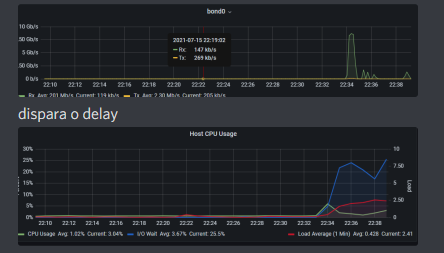
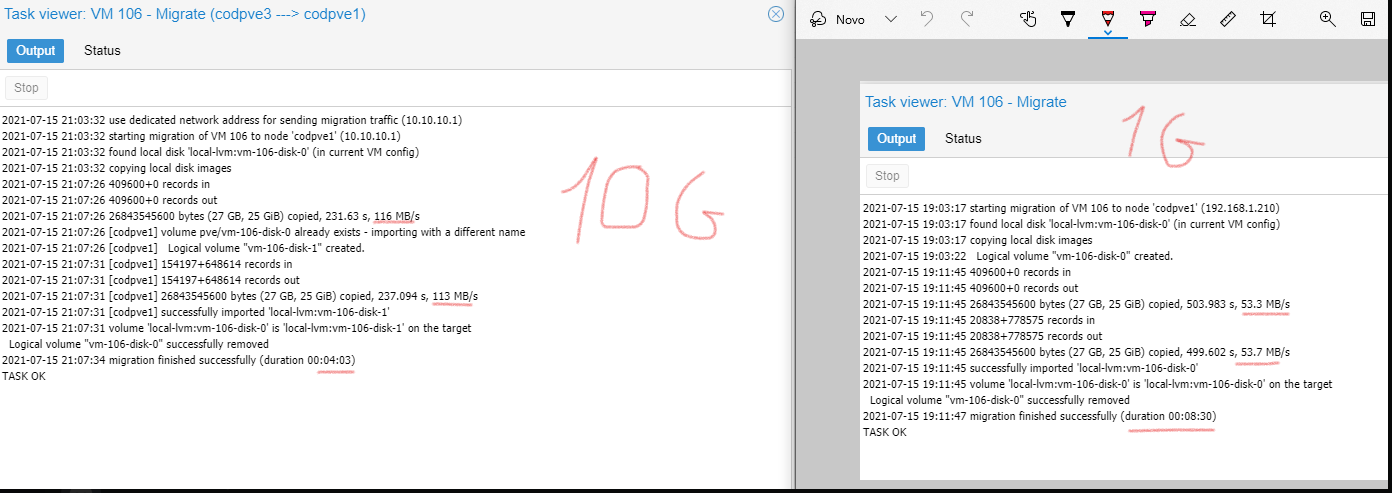
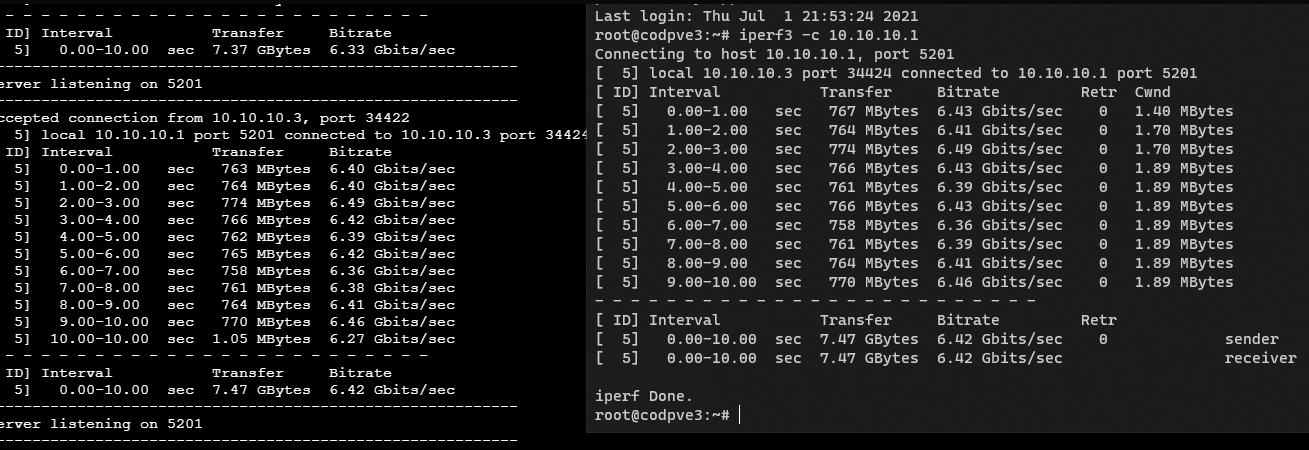
Todos os testes que fiz o problema nunca foi na trasferencia entre os nós, o problema era sempre no sincronismos dos mesmos, o upgrade para 10Gib acabou por não ter uma melhoria muito grande em comparação com 1Gib porque transferia rapido, mas depois demorava quase o mesmo a fazer o sync.
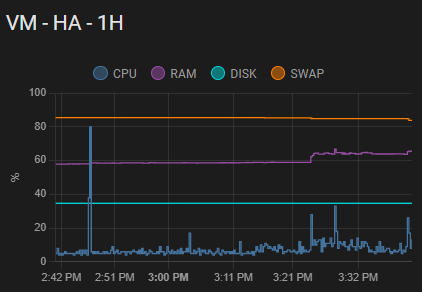
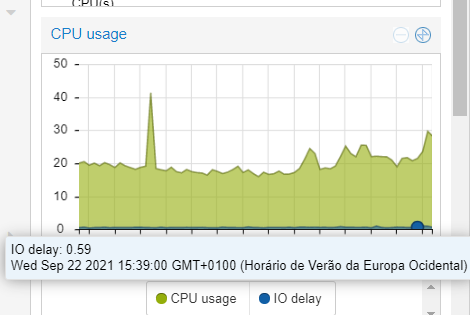
Após alguma investigação, (o proxmox tem lacunas a reportar o disk write/diskread) em LXC o problema estava tanto no HA como no LXC mariadb e influxdb, como referi, tenho muitos sensores que guardam os dados de 15 em 15 segundos, o que usando hoje num nó e antes numca foi problema para o hardware usado (hdd) assim que tentei zfs/ceph mesmo alterando o disco para ssd foi problemático…
Print que ontem não deu para colocar
Em suma, proxmox é fixe mas quando se começa a pensar em cluster (seja ceph seja nfs) sugiro pensar duas vezes, principalmente em homelab em que o hardware será sempre mais modesto… sendo que o problema pode não ser do hardware e mais do que lá se pretende correr.
Outra questão a ter em conta é que HA no proxmox só com VM com LXC não é possivel, e portanto ha sempre off → move → on