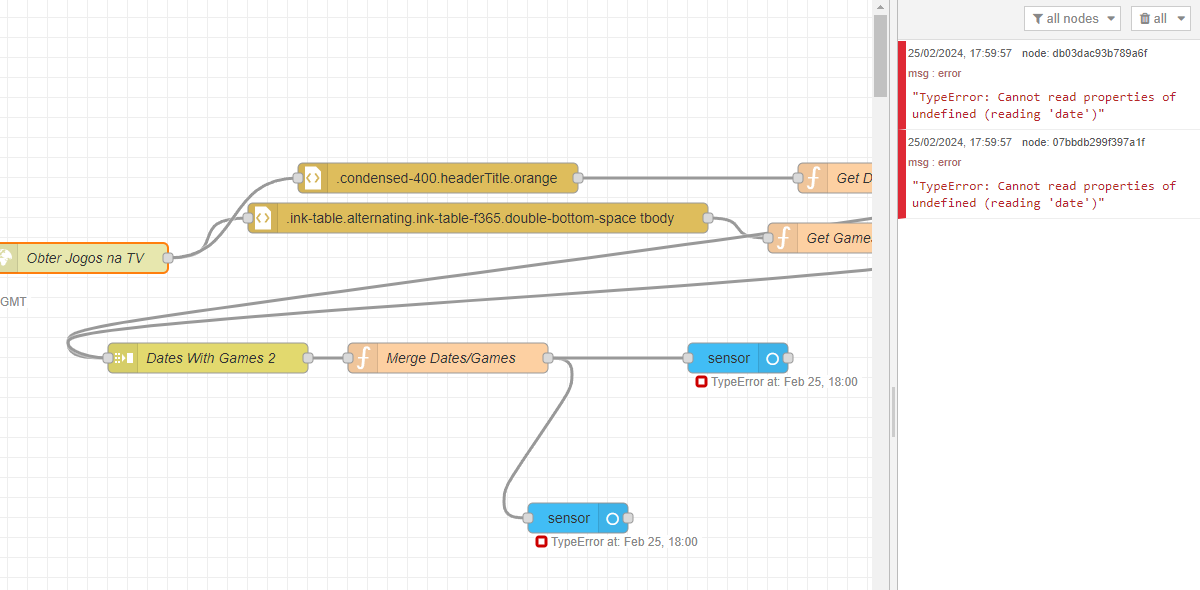
Esqueci-me de mencionar a atualização do Scrape’s sensor…
Não sei qual é o ratio de atualizações que tem de forma inicial/standard mas é boa prática desabilitar a actualização automática, indo à integração “Scrape”, e à direita do sensor carregar nos 3 pontos. Aí tens as opções:
- Reload
- Rename
- System options
- Disable
- Delete
Vais a “System options” e desabilitas a segunda opção: “Enable polling for updates.”
A forma ideal é através de uma automatização:
alias: Scrape - Automation
description: ""
trigger:
- platform: time_pattern
hours: /12 #mete o número de horas,dias, etc., que desejares a actualização
condition: []
action:
- service: homeassistant.update_entity
data: {}
target:
entity_id:
- sensor.fcporto #exemplo - altera para o que tens
mode: single